Harmonising data in collaborative research projects
In LongITools, we have access to data on over 11 million EU citizens, from 24 different research studies. These studies were built independently from each other so there are differences in the way the data has been collected. In research, collaboration between studies increases statistical power and ensures a greater diversity of people, environments and life situations are considered when making conclusions about any phenomenon of interest. Collaboration facilitates cross-study comparisons, validation, and replication making research more reliable and applicable more widely. However, there are complexities when bringing together different studies or data sets to answer specific research questions. One way to overcome some of the complexities is to try to harmonise the data.
Data harmonisation is the process of making different variables consistent and comparable across different sources or study populations. The goal of data harmonisation is to make it easier to combine and analyse data from different sources, and to reduce the risk of errors or inconsistencies that can arise when working with non-harmonised data. It is commonly used in research, especially in fields such as epidemiology, genetics, and social sciences, where data from multiple sources may be combined to form a larger dataset.
Data harmonisation process
The data harmonisation process can contain the following steps:
Identifying the variables of interest
There are hundreds if not thousands of variables in each study so instead of trying to harmonise everything, together we discussed the research questions we wanted to focus on first and created a list of variables most relevant to those questions.
Defining variable names and labels in a consistent manner across datasets
We wanted to have a uniform way of naming the variables so, for example, the name of variables related to participant’s physical activity start with letters pa (from physical activity) followed by underscore and the level of activity, e.g., pa_mod refers to moderate physical activity and pa_vig refers to vigorous physical activity.
Converting variables to a consistent unit of measurement
It is important to use the same units when combining several data sets for one analysis. Therefore, we decided to use for example, centimetres instead of metres for a person’s height and days instead of weeks for gestational age.
Recoding categorical variables to ensure consistency in the categories or levels
Like in the previous point, variables containing groups must have the same groups between the studies. For example, we decided to group a person’s education in high, medium, and low based on the International Standard Classification of Education 97/2011. Most of the studies had more than three groups in their education variable so they had to recode their existing groups into three levels.
Applying quality control checks to ensure the accuracy and completeness of the data
Harmonisation is a pedantic and sometimes laborious process as we often need to combine several variables into one. It is only human to make errors during the process so checking the harmonised data regularly and comparing it to the original is crucial to obtain reliable and good quality data.
Example of harmonisation of physical activity between four different studies
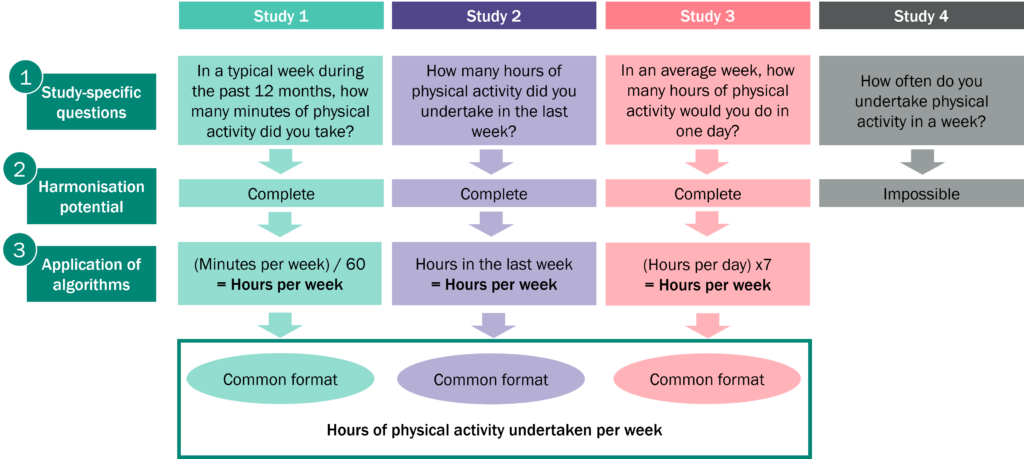
Modified from https://www.measurement-toolkit.org/concepts/harmonisation
Harmonisation waves in LongITools
Wave 1 – First set of harmonisations
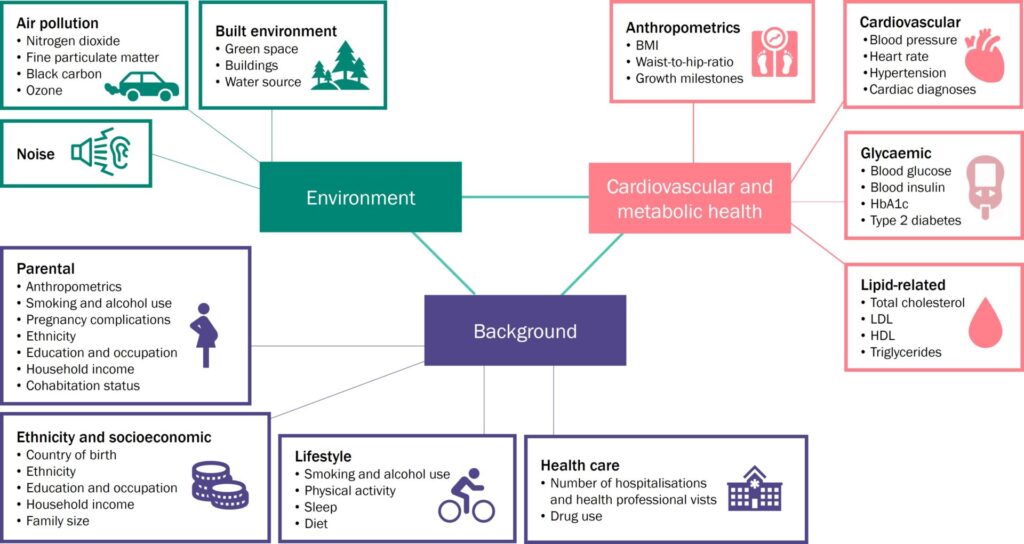
To begin the process of harmonisation, we first discussed with all researchers which variables were the most important ones to be harmonised for analyses. These included variables related to the study participants’ background, anthropometry (body measurements) and clinical and health care-related factors. Given that the focus of LongITools is on cardiovascular and metabolic health, naturally the first set of harmonised variables focused on the factors associated with those, such as weight, height, blood glucose, insulin and lipids, blood pressure, history of diabetes and cardiovascular diseases and so on.
Harmonisation protocols were created following the recommendations in the EU Child Cohort Network Variable Catalogue. If not already available in the catalogue, harmonisation protocols were established based on other previous projects, scientific literature, expert knowledge, and international classification systems.
Wave 2 – Environmental exposures
To explore the exposome, i.e., environmental factors we are exposed to across the life-course that may predispose or protect people from diverse cardiovascular and metabolic conditions, we need to be able to measure the environment. As part of other projects which some of our partners are involved in, such as the European Study of Cohorts for Air Pollution Effects and the Effects of Low-Level Air Pollution: A Study in Europe, we have utilised pan-European models to generate estimates for air pollution, noise and the built environment. These models use satellite images, local monitors, and traffic maps to provide information about the exposures of interest. We generated these estimates for each study participant who has provided consent and for each address they have lived in.
Harmonised LongITools variables
Conclusion
Data harmonisation is a vital step when using several data sources to understand the relationship between environment and health. Now that we have this valuable resource of harmonised data, demonstrated in one of LongITools’ key outputs the Metadata Catalogue, we can work to unravel the complexity of the exposome. By harmonising the data and promoting collaboration, we aim to strengthen the research efforts and enhance the validity of our findings.
by Justiina Ronkainen, University of Oulu
Glossary
Anthropometry: the scientific study of the measurements and proportions of the human body.
Blood lipids: important markers of cardiovascular health. Commonly measured and monitored blood lipids are total cholesterol, high- and low-density lipoprotein cholesterol (HDLc and LDLc), and triglycerides.
Epidemiology: study on the distribution, determinants and patterns of health-related events, states, and processes in populations. It can include for example study of the occurrence and spread of diseases or other factors that influence health. Epidemiology is crucial in identifying and assessing public health issues, developing strategies for disease prevention and control, and evaluating the impact of public health programs and policies.
Metabolic: metabolism encompasses all the chemical reactions that take place in an organism (including all of us), collectively known as metabolic pathways. These pathways convert molecules into different products and are essential for the proper functioning and survival of organisms.
Metadata Catalogue: software tool used for managing, organising, and searching the metadata in the field of epidemiology. Metadata is the information that describes the way data was collected. It includes for example details about experimental protocols, sample characteristics, data processing methods, and other information that helps interpret and understand the data.
Statistical power: the ability of a statistical test or analysis to detect a true effect or relationship when it exists.
Variables: measurements or pieces of information collected on each study participant, such as height, address, or number of children.